Version 2: Flow Matching
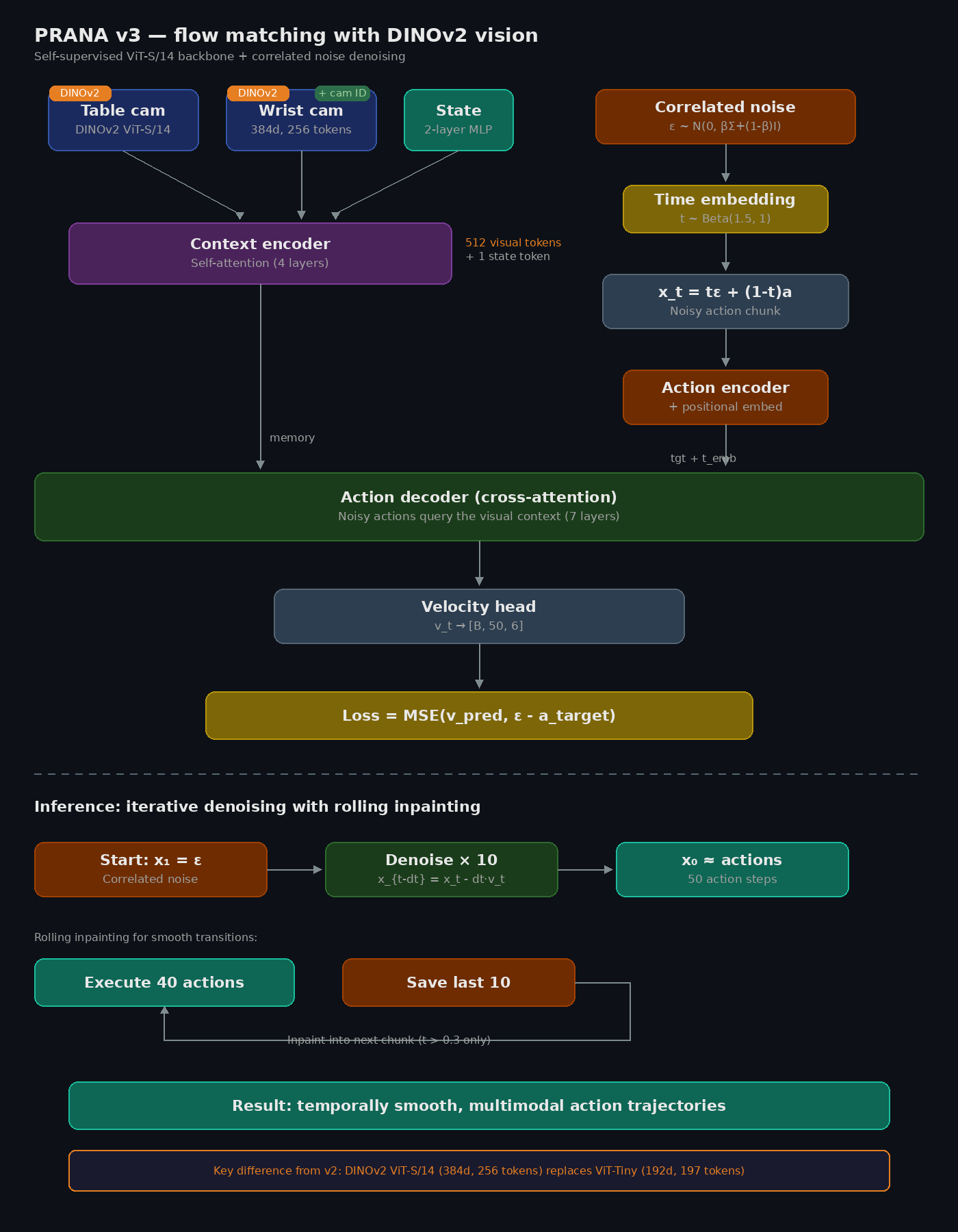
PRANA v2
Iterative denoising with
correlated noise
Instead of predicting one average trajectory, the model starts from noise shaped like real robot motions and refines it step by step into precise actions. I added cross-attention so the decoder looks at the scene before it decides what to do.
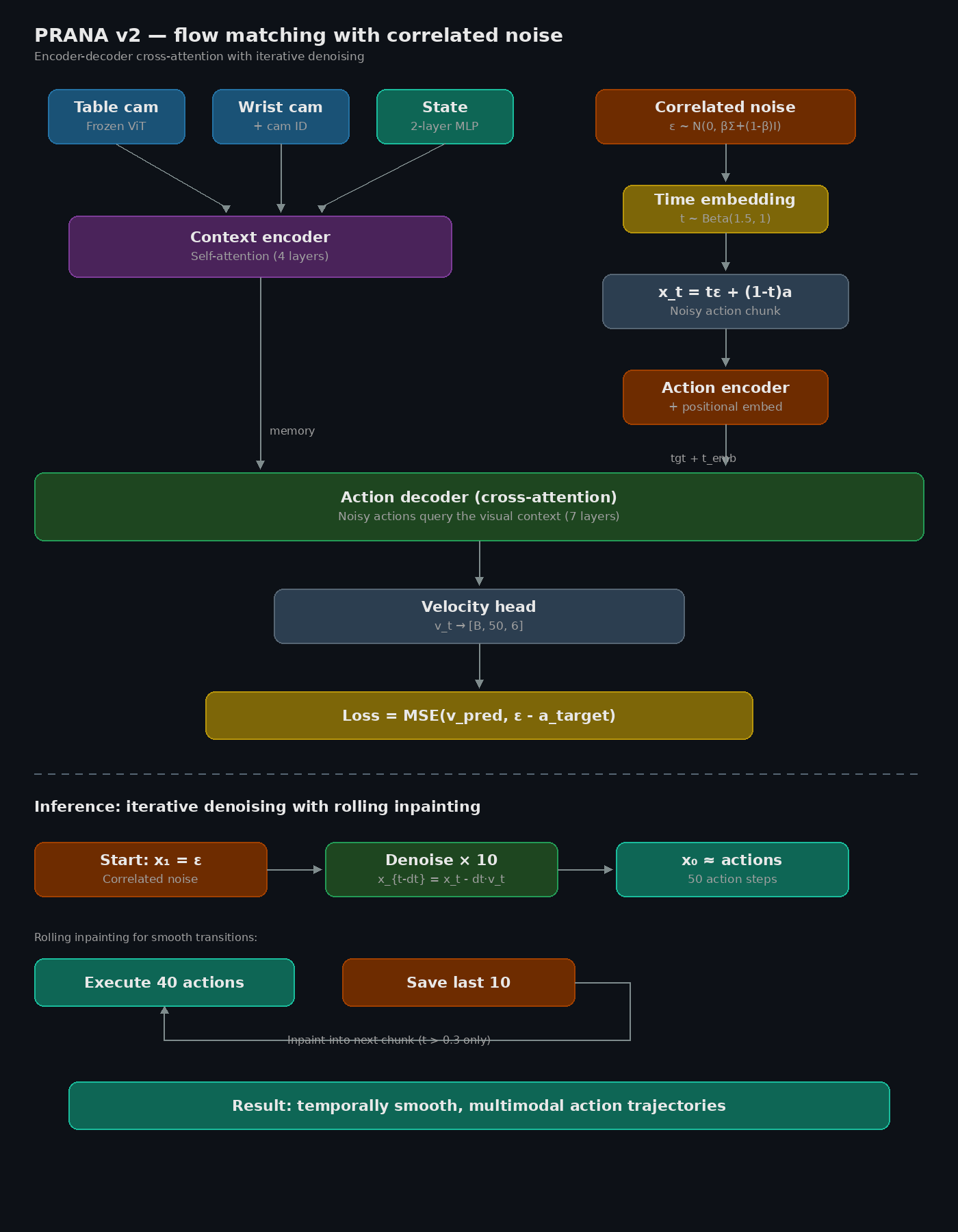
v2 architecture: context encoder plus cross-attention action decoder with flow matching
- Frozen ViT-Tiny with camera ID embeddings
- 4 layer context encoder (self-attention over vision plus state)
- 7 layer action decoder (cross-attention to context)
- Flow matching: 10 Euler denoising steps at inference
- Correlated noise from Cholesky decomposition of action covariance
- Rolling inpainting: execute 40, save 10 for smooth transitions
- ~11M trainable params, 100K training steps
- 22ms per chunk inference on RTX 5060
v2: picks up screwdriver and places in box